
今回は「〜第二章〜ファイルとデータベース」を解説します。
第一章をまだみてない方は、まずは第一章から見てください!

本記事ではIT知識ゼロでもわかりやすいように解説していますので、ぜひ参考にしてください。
初学者には動画講義が圧倒的にオススメ!
僕も受講したアガルートでは「経営情報システム単体」の受講も可能!
- 全額返金・お祝い金制度
- 業界で安価な価格設定
- 平均よりも高い合格率(1次試験:1.5倍 2次試験:3倍)
- 完全オンライン完結
- 専用アプリあり
情報システムの目的はデータを処理すること。
ソフトウェアはデータを処理することで動作している。
コンピュータ上でデータを記録しておく入れ物を「ファイル」という。
複数人でデータを共有できる仕組みを「データベース」という。
今日の学習ではこの「ファイル」と「データベース」を中心に見ていきます。
ファイル
ファイルは皆さんも馴染みがある概念だと思います。
例えば、ExcelやWordを作成し、保存した時に作成されるのがファイルです。
ファイルはOSで管理されており、通常は保存などの操作をすることでハードディスクに格納されます。
ファイルの分類
ファイルには様々な種類があります。
形式別に分類すると、大きくテキストファイルとバイナリファイルに分けられます。
- テキストファイル
→文字が格納されているファイル。Windowsのメモ帳などのテキストエディタで開いて編集可能。
- バイナリファイル
→コンピュータで使用される2進数(バイナリ形式)でデータが格納されているファイル。テキストエディタで開いても文字として認識できない。画像や音声はバイナリとして格納されている。
ファイル名と場所
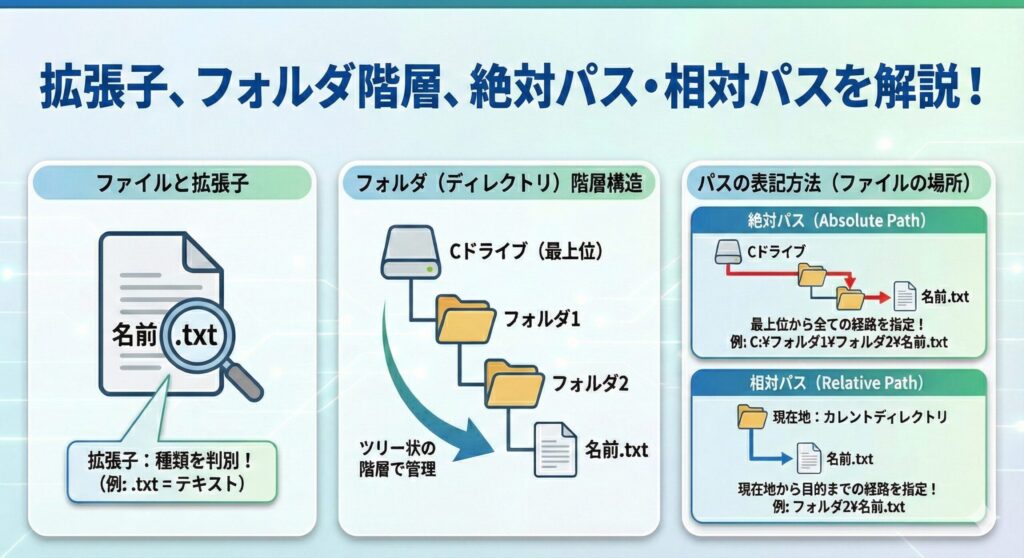
ファイルにはファイル名がついており、種類を表す拡張子がつけられているんだ!
- 拡張子
→ソフトウェアがファイルを扱う際に、ファイルの種類を判別できるようにしたもの。例えば、テキストファイルは「名前.txt」という拡張子。
ファイルはフォルダ(またはディレクトリ)という階層構造の中で管理される。フォルダはファイルの置き場所になるもので、OSの中でツリー上の階層構造になっている。
ソフトウェアが特定のファイルにアクセスする場合には、フォルダ名とファイル名を指定することでファイルを特定する。
ここでフォルダとファイル名を繋げたものをパスという。ファイルやディレクトリの所在場所を示す表記には絶対パスと相対パスがある。
- 絶対パス
→階層の最上位のディレクトリを基点として、目的のファイルやディレクトリまで、すべての経路をディレクトリ構造で示す。
例えば、Windowsにおいて絶対パスで表記する場合。「C:¥フォルダ1¥フォルダ2¥名前.txt」となる。これは「Cドライブ」にある、「フォルダ1」に含まれる、「フォルダ2」に含まれる、「名前.txt」を指定している。
- 相対パス
→現在作業を行なっているディレクトリを基点として、目的のファイルなどに、全ての経路をディレクトリ構造に従って示す。
例えば、先ほどの例でカレントディレクトリがフォルダ1の場合に相対パスで表記すると「フォルダ2¥名前.txt」となる。
テキストファイル
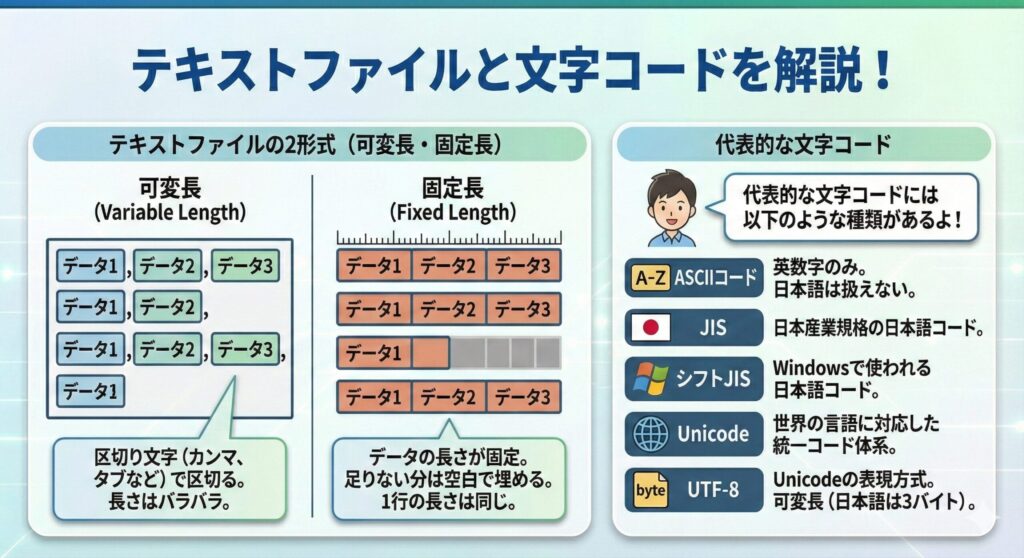
表などのデータを格納するためのテキストファイルには可変長と固定長の2つの形式があるんだ!
- 可変長
→データの区切りが、カンマやタブなどで区切られたファイル。
- 固定長
→固定長ファイルはデータの長さが固定されている。固定長ファイルでは、行のデータはデータ長で項目が指定される。データの長さが足りない場合は空白で埋められるため、1行のデータ長は同じになる。
- 文字コード
→テキストファイルでは、文字情報が文字コードによって格納されている。コンピュータでは、全ての情報は0と1の2進数で格納されている。
代表的な文字コードには以下のような種類があるよ!
- ASCIIコード
→英数字を扱う最も基本的な文字コード。英語圏ではASCIIコードで、通常の文章を表すことができる。日本語を扱うことはできない。
- JIS
→JIS(日本産業規格)で定められた日本語の文字コード。
- シフトJIS
→Windowsで使用されている日本語の文字コード。
- Unicode
→世界の主要な言語に対応したコード。世界で共通の統一コード体系と位置付けられる。
- UTF-8
→Unicodeをパソコンで扱うための数値変換の方式(文字コード)の1つ。一文字を1~4バイトの可変長で表現でき、日本語は3バイトで表現する。
バイナリファイル
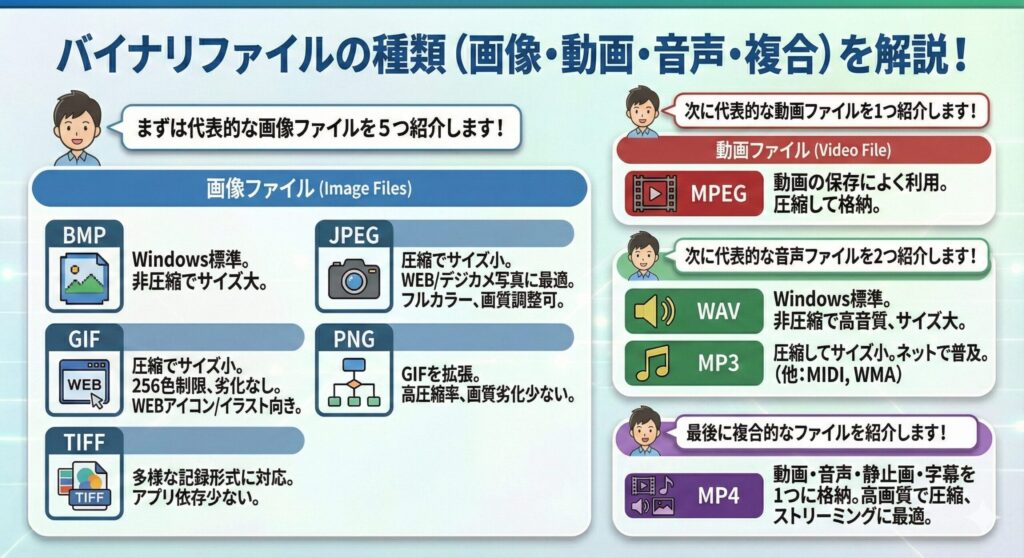
バイナリファイルには、画像ファイル・動画ファイル・音声ファイルなど様々なものがある。
画像ファイルには、BMP(ビットマップ)・JPEG(ジェイペグ)・GIF(ジフ)などがある。
まずは代表的な画像ファイルを5つ紹介します!
- BMP
→Windowsで標準的に使われる画像ファイル。基本的には圧縮されていないため、ファイルのサイズが大きくなる。
- JPEG
→JPEGも画像ファイル。圧縮されているのが特徴。ファイルのサイズが小さくなるため、WEBサイトでよく使用される。JPEGはフルカラーが使用できるが、圧縮する際に画質を落とすことでサイズを小さくしている。圧縮率は指定できるため、目的に合わせた画質とサイズに調整できる。例としては、デジカメの写真によく使われている。
- GIF
→GIFも画像ファイル。圧縮されているのが特徴。最大256色しかつかえない制限があるが、圧縮による画質の劣化はない。例としては、WEBサイトのアイコンやイラストに使われている。
- PNG
→同様に静止画像を取り扱うデータ形式。データは圧縮されて保存される。ネットワーク経由での使用を想定して、GIFの機能を拡張したもの。圧縮率が高い割に画質の劣化が少ないのが特徴。
- TIFF
→記録形式の異なる様々な画像を保存できるデータ形式。画像データの先頭に、画像の記録形式に関する属性が記録されている。そのため、様々な形式の画像データを扱え、アプリケーションへの依存が少ないのが特徴。
次に代表的な動画ファイルを1つ紹介します!
- MPEG
→動画を保存する際によく用いられる。動画はデータ量が大きくなるため、動画データを圧縮して格納している。
次に代表的な音声ファイルを2つ紹介します!
- WAV
→Windowsで標準的に使われる音声ファイル。通常は圧縮しないため、音質は高いが、サイズが大きくなる。
- MP3
→音声を圧縮して格納する方式。サイズが小さくなるため、インターネットでよく使われている。そのほかの音声ファイルとしては、音楽データに利用されるMIDIや、Microsoft社が独自開発した圧縮方式であるWMAがある。
最後に複合的なファイルを紹介します!
- MP4
→MPEG-4規格の一部として策定された、動画・音声・静止画・字幕などの情報をひとつのファイルに格納することができるファイル形式。MPEGなどの動画データ、MP3などの音声データ、JPEGなどの画像データをまとめて格納できる。MP4は高画質のままデータを圧縮できるため、ビデオストリーミングサービスや動画のダウンロードなどに広く使われている。
データベース
データベースとDBMS
データベースは、複数人でデータを共用するもの。データベースを管理するソフトウェアをデータベース管理システム(DBMS)という。データベースを利用するには、DBMSというソフトウェアを導入し、データベースを作成する。
データベースのメリット
- メリット1
複数のユーザが同時にデータを参照・更新できる。
仮に、複数ユーザが同じデータを更新しようとした場合は、先に更新の命令を出した人が更新を完了するまでは、他の人が同じ行を更新できないようにする。これをロックと呼ぶ。
ロックによって、同じデータが同時に更新されることを防ぎ、データの整合性を保っている。
- メリット2
データを一元管理できる。
データベースの場合は、データが一ヶ所にあるため、データの一元管理がしやすくなる。
- メリット3
セキュリティを高められる。
データベースでは、アクセスできるユーザを制限したり、アクセスできる範囲や処理内容を制限することが可能。
リレーショナルデータベース(RDB)
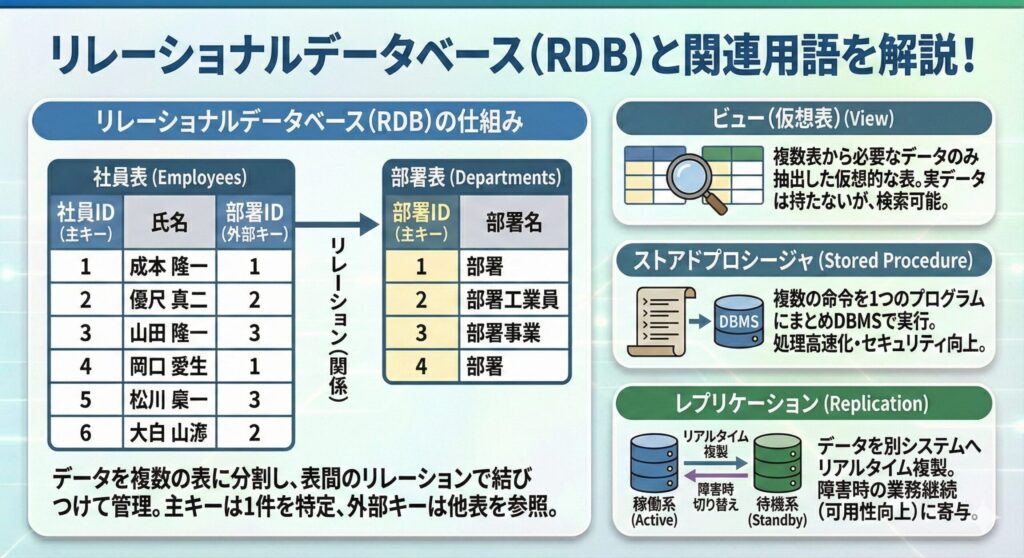
データベースには種類があるが、リレーショナルデータベースが一般的に使われている。リレーショナルデータベースは、データを複数の表と表の間の関係で表す。
データをある一定にまとまりである表に分割し、表の間の関係を定義することで、様々なデータを格納することができる。
表の間の関係のことをリレーションという。リレーションは参照元の表のある列から、参照先の表のある列を参照するもの。
リレーションの参照元の列のことを外部キーという。
各表で、その列の値によって1件のデータが特定できる列のことを主キーという。
- ビュー(仮想表)
データベース内の複数の表から必要なデータのみを抽出して新たに作成した仮想的な表のこと。表と違い、実データは格納されていない。しかし、利用者側から見ると、表と同じように検索することができる。
- ストアドプロシージャ
データベースに対する複数の命令を一つのプログラムにまとめて、DBMSで実行するもの。データベースに対する処理を高速化することができ、セキュリティ向上にもつながる。
- レプリケーション
データベースのデータを別のシステム上にリアルタイムで複製すること。レプリケーションを実行し、稼働系と待機系の2システムを用意しておくと、障害発生の際にも切り替えて業務継続が可能となる。
正規化
リレーショナルデータベースを使用するには、最初にデータベースを設計・構築する必要がある。
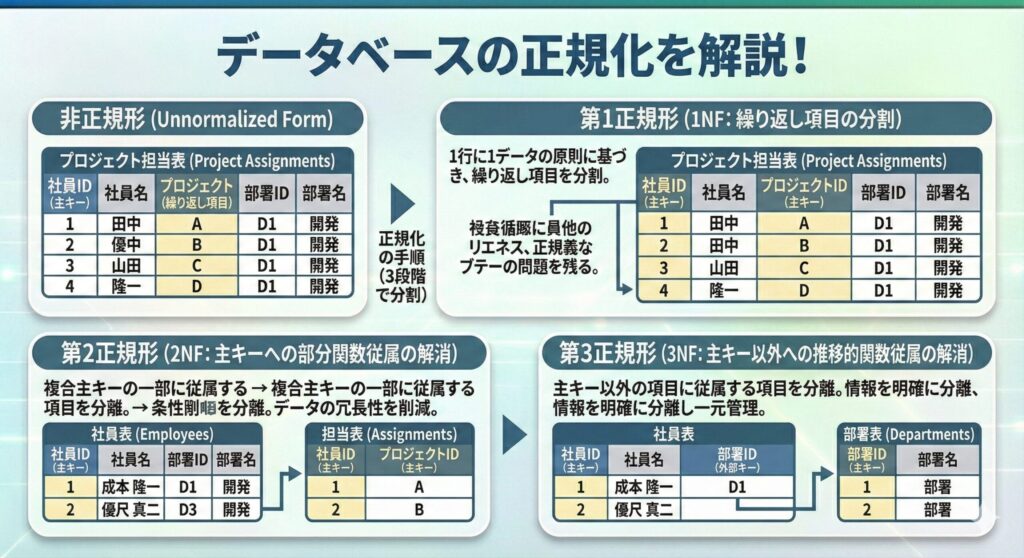
データベースの設計では、アプリケーションで必要なデータを洗い出し、表とリレーションを定義していく。表をどれくらい細かくしていくかがポイント。ここで、表を分割していく手順を正規化という。正規化をすることで、データの重複をなくし、データを一元管理することができる。
正規化されていない表のことを、非正規形という。正規化では、非正規形の表を3段階の手順で分割していく。このそれぞれの段階を「第1正規形」「第2正規形」「第3正規形」と呼ぶ。通常のデータベース設計では、第3正規形まで正規化を行うことが多い。
- 第1正規化
第1正規化は、繰り返し項目を分割する手順。繰り返し項目とは、1つの行の中に複数繰り返されているデータのこと。リレーショナルデータベースでは、1行に1種類のデータを格納するのが基本のため、繰り返し項目を分割する必要がある。
- 第2正規化
第2正規化は、表の中で生じている依存関係を整理し、データの冗長性をなくすために、別の表に分割する手順。
主キーに部分的に従属している項目を分離するのが第2正規化。
- 第3正規化
主キー以外の項目に従属する項目を、別の表に分割する手順。この手順によって、情報が明確に分離され、データを一元的に管理できるようになる。
「正規化」って難しく聞こえるけど、要は『部屋の片付け』と同じだよ! 散らかった部屋(非正規形)を、・第1段階:ゴミを捨てる(繰り返しをなくす) ・第2段階:服はタンスへ(部分関数従属をなくす)・第3段階:小物は引き出しへ(推移的関数従属をなくす)って整理整頓して、「どこに何があるか一発で分かる状態」にする作業なんだ。
SQL
データベースは、Excelなどのファイルと違い、データベースにアクセスする言語によってアクセスする必要がある。この言語のことをSQLという。SQLには大きく分けて、データベースや表の作成などを行う管理用のデータ定義言語(DDL)と、データの参照・更新などを行うデータ操作言語(DML)がある。
- DDL
表を作成したり、変更、削除する時などに使用する。通常、DDLはデータベース管理者や設計者が使用する。
- DML
DMLは次の4種類がある。SELECT(検索)、INSERT(挿入)、UPDATE(更新)、DELETE(削除)。これらは、データベースの表を検索・更新する際に使う。DMLは、アプリケーション開発者やデータベースの利用者が使う。
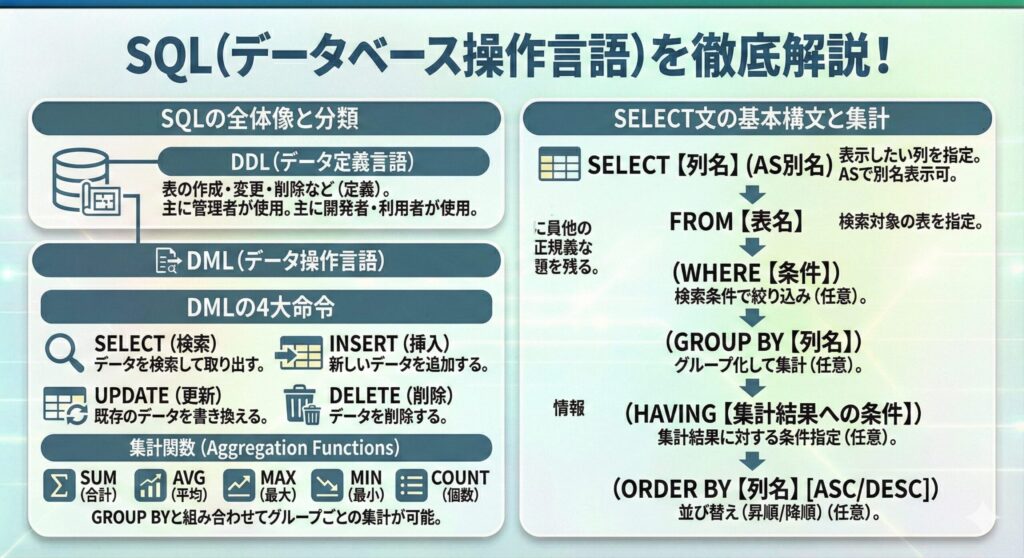
- 基本的なセレクト文
SELECT文は、データベースから欲しい言語を取り出す言語。SELECT文でデータベースに検索することにより、データを表の形で取り出すことができる。基本的な構文は以下の通り。
SELECT【列名】(AS別名)
FROM【表名】
(WHERE【条件】)
(GROUP BY【列名】)
(ORDER BY【列名】)
括弧内の文は、必要なときにはこの順で書き、不要な時は書かないもの。
SELECT句の後の列名には、検索したい表の列名を記入する。カンマで区切ることで、複数指定することも可能。
AS別名は、列名を別名に変更して表示できる。
FROM句の後の表名には、検索したい表名を記入する。
WHERE句の後の条件には、データを検索する条件を記入する。WHERE句を指定した場合、条件に該当する行だけが検索される。
GROUP BY句では、列名でグループ化することが可能。
ORDER BY句では、特定の列の値で昇順、降順に並び替えて表示することが可能。
※昇順はASC、降順はDESCをつける。
- 集計関数
SELECT文では、複数の行の集計をすることも可能。例えば、商品の販売履歴を基に、商品ごとの販売数量を合計したり、平均値を計算することができる。このような集計を行う場合は、GROUP BY句と集計関数を使用する。集計関数には、合計(SUM)、平均値(AVG)、最大値(MAX)、最小値(MIN)、データの個数(COUNT)など様々なものがある。集計結果にさらに条件をつけるには、HAVING句を使う。
ロールバックとロールフォワード
データベースでは、障害や異常が発生した場合に、データの整合性を保ちながら、正しい状態に回復させる仕組みがある。
代表的なものがロールバックとロールフォワード!
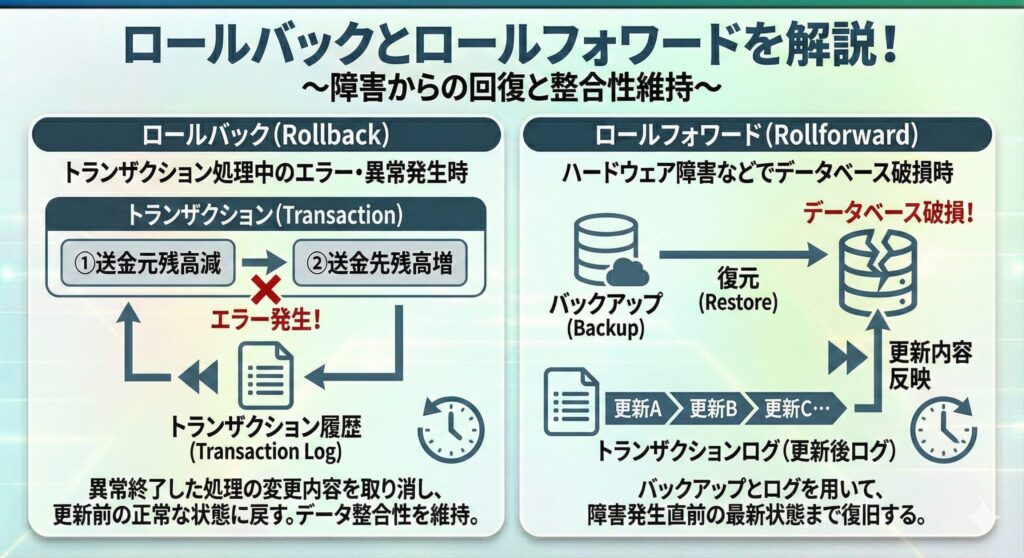
- ロールバック
トランザクション処理中にエラーや異常が発生した時に使う方法。
トランザクションとは、複数の処理をひとまとまりとして扱う単位のこと。例えば、振込処理では「送金元の残高を減らす」と「送金先の残高を増やす」という2つの操作を1つのトランザクションとして処理する。
処理の途中でエラーが発生した場合は、トランザクションの履歴を使って、異常終了した処理の変更内容を取り消し、データを更新前の正常な状態に戻すことで整合性を保つ。
- ロールフォワード
ハードウェア障害などでデータベースが破損した時に使う復旧方法。
定期的にバックアップを取得していることを前提としている。まず、バックアップを基にデータベースを復元する。次に、バックアップ以降の更新内容を反映させるために、トランザクションログを使用する。この時に用いるのが、トランザクションログに記録された更新後ログ。このログには更新処理後のデータが時系列で保存されており、障害発生直前の最新状態まで復旧することができる。
構造化データと非構造化データ
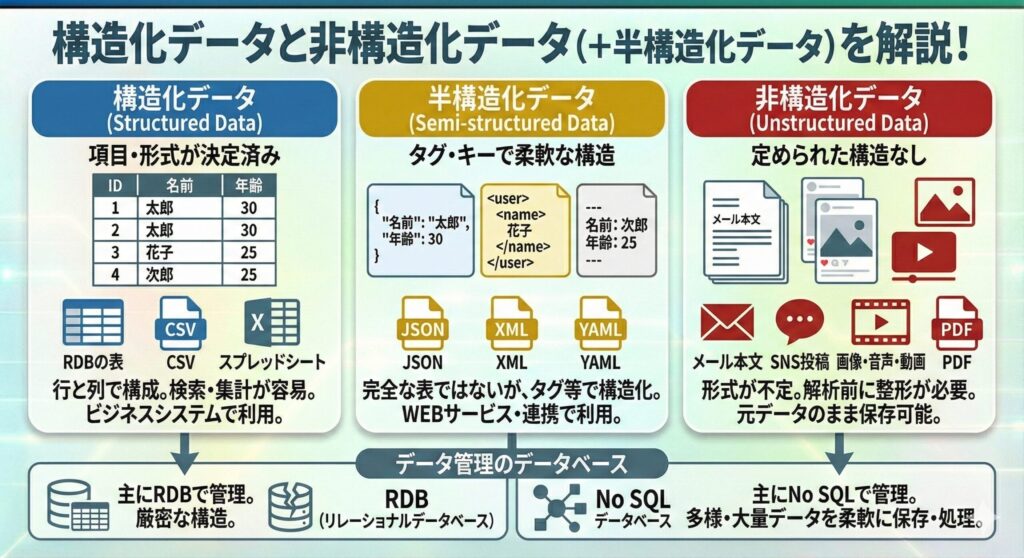
データはその構造の明確さに応じて、構造化データ・半構造化データ・非構造化データに分けられる。
- 構造化データ
あらかじめデータの項目や形式が決められたデータ。リレーショナルデータベースの表、CSVファイル、スプレッドシートなどが代表例。行と列で構成され、各列にはデータ型が定義されている。検索や集計が容易で、ビジネスシステムや基幹業務で広く利用される。
- 非構造化データ
あらかじめ定められた構造を持たないデータ。メール本文やSNS投稿、画像、音声、動画、PDFなどが代表例。形式が一定ではなく、従来のデータベースにそのまま格納・検索が難しいため、解析の前に整形や構造化を行う。一方で、元データをそのまま保存できる柔軟さがある。
- 半構造化データ
構造化と非構造化の中間に位置するデータ。完全に整形された表形式ではないが、タグやキーを使って柔軟に構造を持たせられるのが特徴。代表的な形式として、JSON、XML、YAMLがある。これらはデータごとに項目を自由に追加でき、WEBサービスやシステム間連携で広く利用されている。
構造化データは主にRDB(リレーショナルデータベース)で管理されるが、半構造化データや非構造化データを取り扱う場合は、No SQLデータベースがよく使われる。No SQLはデータの形式や構造をあらかじめ厳密に決めなくても良いため、多様で大量のデータを柔軟に保存・処理することができる。
コミットと2相コミットメント
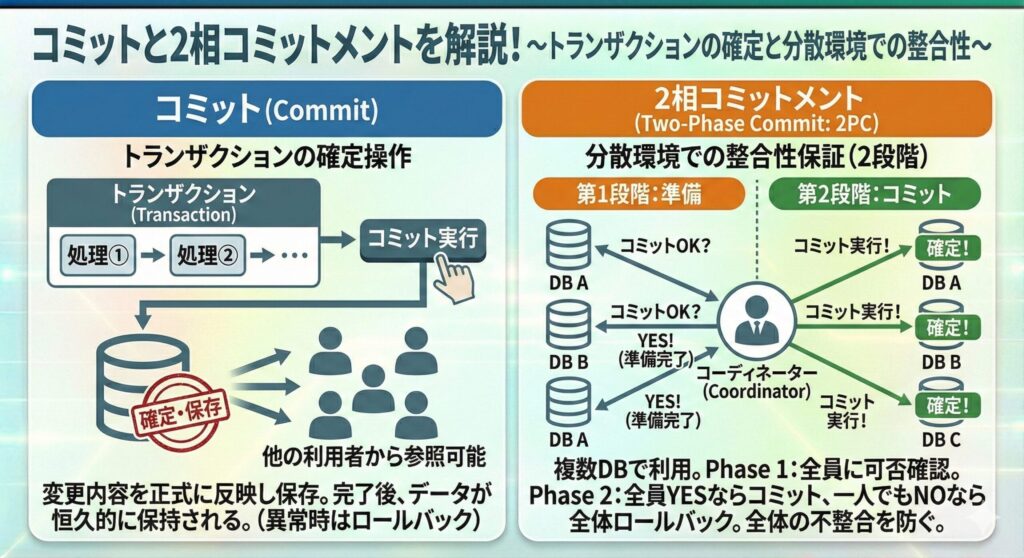
データベースでは、トランザクションの処理結果を確定させるため、コミットという操作を行う。
- コミット
トランザクションで行った変更内容を正式に反映し、データベースに保存すること。一度コミットされると、その内容はほかの利用者からも参照できるようになり、データが恒久的に保持される。
例えば、振込処理が全て正常に完了した時点でコミットを実行すると、送金元と送金先の口座残高が確定し、正しい状態が保証される。
一方、処理の途中で異常が起きた場合は、ロールバックにより変更を取り消す。このように、コミットはトランザクションの確定操作であり、データの信頼性を保つ重要な仕組み。
- 2相コミットメント
コミットの考え方を複数のデータベースにまたがる環境に拡張した仕組み。分散システムでは、複数のサーバやデータベースが同じトランザクションに関与することがある。その場合、どれかひとつだけがコミットされて他がロールバックされると、不整合が発生してしまう。これを防ぐため、2相コミットメントでは2段階の手順を踏む。
まず、コーディネーターと呼ばれる代表役が、すべてのデータベースにコミットできるかを確認する。全員がYESと応答した場合のみ、実際のコミット命令を出して確定させる。ひとつでもNOがあれば、全体をロールバックして取り消す。このように、2相コミットメントは分散環境でも、全体の整合性を保証する仕組みとなる。
- ビッグデータ
既存の技術では管理困難な大量のデータのこと。顧客データなどの表形式で表すことができる構造化データだけでなく、テキストなどの非構造化データなど、全てビッグデータに含まれる。
ビッグデータには多量性・多様性・リアルタイム性の3つの特性があり、これをビッグデータの3Vという。具体的な活用場面としては、BtoCやMtoMがある。
例えば、Amazonや楽天では、会員データや購買履歴などのデータを収集し解析することで顧客一人一人にオススメ商品や売れ筋商品などの情報を提案している。また、自動販売機の遠隔監視でも、蓄積される膨大なデータを分析し、需要予測に役立てようとする動きがある。
表計算ソフトウェアの関数
- IF関数
条件によって処理を分ける際に使用される。
構文:IF(条件式,判定が真の場合の処理,判定が偽の場合の処理)
- COUNT IF関数
条件に一致した値の個数を数える際に使用される。
構文:COUNT IF(対象範囲,条件式)
まとめ
今回は、「〜第二章〜ファイルとデータベース」を解説しました。
経営情報システムの学習のポイントとしては、身近な例で覚えることです。
文章で説明されてもよくわかりませんが、例がわかればイメージができます。
僕の記事では例も出して解説しておりますので、他の記事も参考にしてみてください!

